ここ1週間、毎日PV(ページビュー)が20万くらいありまして、とんだPVバブルとなっております。今月の合計PVは200万くらい。昨年の12月にマネージドの専用サーバからAWS(Amazon Web Service)にサーバを引っ越しまして、今回はそのおかげでアクセスが大きく伸びました。いい機会なので実録レポートをお届けします。
サーバエラーが出だすと拡散は止まってしまう
いままで何度か書きましたが、一般的なレンタルサーバでは、共有の安めのだとAnalyticsで同時アクセス300人ほど、高めで400人ほど。専用サーバのそこそこいいので1000人くらいで503が出始めます。よくある
503 – service unavailable
という表示です。このときアクセスしてきた人は、めちゃくちゃ遅く表示されるか、またはこのメッセージが出て表示されなくなります。去年の8月27日のロリポップ事件の時の時間別推移です。このときは専用のマネージドサーバ。
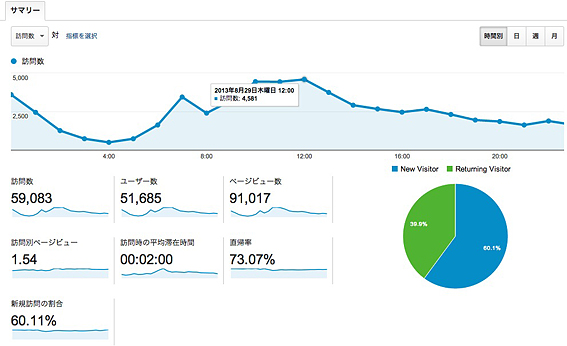
昼前に書いたブログがバズり始め、Analyticsで昼にピークを迎えました。12時台の総訪問者数4581人。リアルタイムでAnalyticsで1200人くらいまでいった時点でサーバが遅くなり始め、アクセスした人の多くに503が出始めて終息に向かいました。終息と言ってもこの日のPVは91000ですが・・・
では、どんなにアクセスが来ても全くサクサクならどうなるかが先週の金曜日の2/21です。
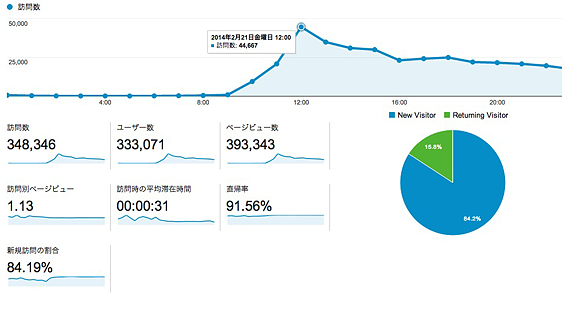
10時頃公開したブログが爆発的に拡散され、こちらもピークは12時台でそのあと下がっているのは同じですが、単位が10倍違う・・・。
12時台の総訪問数は44667人。1日のPVは40万弱です・・・・
拡散が始まったときにサーバにエラーが出だすと、そこで拡散に急ブレーキがかかり、本来獲得できる見込みの来訪者を失ってしまうわけですよ。2/21の例で言うと、もしこれがAWSでなかったら、11時前には拡散は停止してたはずです。それがなかったのでここまでアクセスが伸びたわけですね。
どうしてAWSにして速くなったのか
AWSは普通のレンタルサーバのように管理画面も無ければなにもないドンガラの状態なので、運用にはエンジニアが必要です。わたしのサーバは雲屋さんというスタートアップしたばかりのAWSの専門チームが担当してくれていますが、サーバはm1.mediumというタイプ、要するにフツーのヤツです。AWSはオートスケーリングといってアクセスが集中した時にサーバの台数が増えてアクセスを分散化させるのですが(私のは早めにCPU50%で働くようになってるそうな)、実は2/21の時でもかなりのところまで1台でいき、マックス2台で処理しました。
この理由は、まずはApacheではなくnginx(エンジンエックスと発音)というWEBサーバとキャッシュをフルに使い、それをカリカリにチューニングしているからだそう。通常のApacheと比較して60倍の処理速度だそうですが、Apacheのほうがノウハウがあるので一般にはこちらがまだメインだそうな。DBは別サーバになっていて、画像もS3です。わたくしエンジニアではないのでこのあたりは突っ込まないでください。
で、仮に2/21くらいのアクセスが来た場合、1台の専用サーバでまかなおうとするとおそらく月10万円以上はするはず。しかしいつもそんなにアクセスがあるわけじゃないとするなら、年間120万円は痛すぎる。なので徹底的にチューニングしたAWSで、必要なときだけオートスケーリングでアクセスを分散化させるわけですね。ちなみに通常の契約だとアクセスの増加によって課金されるのですが、わたしと雲屋ネットワークさんの契約をよく見たら固定になってました。フツーの専用サーバくらいの価格でして、さきほど「今月大丈夫?」と聞きましたら「まだAmazonから請求来てないですが赤字かもしれません」とのことでした。www そんな人の良い雲屋ネットワークさんにご用の方はご紹介しますのでメッセージください。ちなみにホリエモンドットコムも立ち上げの構築を担当してもらいました。
さて、こんなAWSですが、そもそもアクセスがたいして望めないサイトには意味が無いです。しかしアフィリエイト収入で生活しているアルファブロガーさんとか、超人気商品を売ってるサイトとか、ニュースメディアとか、そういうところにはオススメ。今回身をもって「拡散させるにはアクセスしてくれた人にストレスをかけないことが大事」ということがわかりましたので、これを糧にまた頑張ります。